7. Modelling Land Use change with socio-economic drivers¶
7.1. Summary of requirements¶
The write-up for the modelling section has 15% of the total marks.
Using the data derived from Landsat data over Shenzhen, calibrate a model that describes urban land use change as a function of a set of socioeconomic factors, following the approach of Seto et al. (2002, 2003) (of primary importance)

Test the model to assess uncertainty (of secondary importance)
7.2. The model¶

Having derived a dataset of urban land use, we can calculate urban land use change per year.
7.2.1. Pre-requisites¶
You will need:
RandRstudiorequired codes and datasets
See this section for details on that.
7.2.2. The Seto model¶
Following the general approach of Seto & Kaufmann (2003), we will build a multi-linear model to attempt to describe the urban land use change per year (the ‘y’ variable) as a function of a number of key socioeconomic factors (e.g. capital investment, land productivity, population, wage rates, etc) (the ‘\(x\)’ variables).
We suppose that we have observation (‘\(y\)’) data for \(N_{years}\) and \(N_{params} - 1\) of socioeconomic factors for each of these years.
So, we will derive a (multi)linear model that we could phrase as:
Equation 1:
where we supply the following information:
\(y\) is a column vector of length \(N_{years} - 1\) with urban land use change per year. The minus 1 is because we must calculate land use change from one year to the next.
\(p_n\) are the model parameters, or ‘weightings’ with \(0 \le n \lt N_{params}\), with one parameter per socioeconomic factor, plus an ‘offset’ (\(p_0\)) that doesn’t depend on these factors.
\(x_n\) are the socioeconomic data per year, with \(0 \lt n \lt N_{params}\) for \(N_{years} - 1\) years (one entry for each year, for each socioeconomic factor). The minus 1 associated with \(N_{params}\) is because we have an additional parameter, \(p_0\).
So there are a total of \(N_{params}\) unknown values (the model parameters \(p_n\)) that we need to estimate to calibrate’ the model.
Following the example in the paper, we will use the following in \(x\):
\(x_1\): Investment in capital construction / population
\(x_2\): value of gross agricultural output / agriculture population
\(x_3\): log(wages in non-state, non-collective units)
\(x_4\): log(average total wage)
\(x_5\): (value of gross agricultural output/Agricultural land) / (value of gross industrial output / Urban land)
This will give a model with 6 parameters that we need to estimate (i.e. 6 unknowns) that we could call \(p_0, p_1, p_2, p_3, p_4, p_5\).
Note that the final term (\(x_5\)) requires that we have data for Agricultural and Urban land, which we will need to derive from the remote sensing data for each year of observation.
The rest of the data will come from official statistics. An example for the years 1987 to 2000 is given below to give you a feel for the sort of information you will be using:
There are many freely available online database for downloading important socio-economic data. Some examples are the Center for International Earth Science Information Network (CIESIN) at Columbia University and the World Bank. The data we will be using here are from the Guangdong Statistical Yearbook.
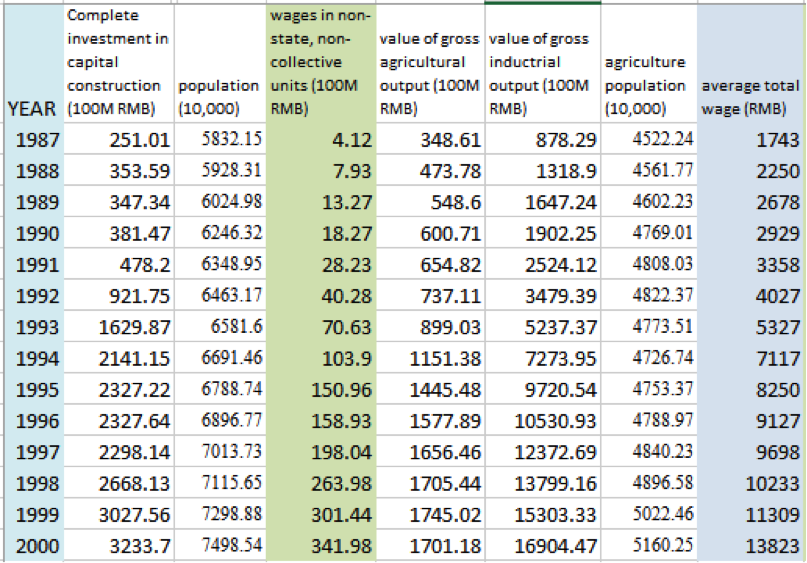
A file with relevant data has been compiled and can be downloaded here.
An example set of classification results are available in the file results-2019.csv that you can also download.
Note that the classification results in the file you can download are the lecturers’ results and must not be used in student analyses (i.e. you must put in your own classification results).
You will only be able to run the model for years that you have driving (socioeconomic) and Landsat data.
7.3. Software¶
To be compatible with the statistics you learn in year 1 (in The Geography Department), we will make use of the language R.
As a reminder to you, the notes from the relevant 1st year practical are available to you on moodle
If you are using a UCL PC, you may want to use the package Rstudio for statistics, but on the UCL Geography (linux) system, we will use R at the command line.
If you are using your own computer, you will probably need to install software for these.
In particular, you need:
Download and install R from https://cran.rstudio.com
Download and install RStudio from https://www.rstudio.com
Make yourself aware of which computer system you are using, and which choice is appropriate for you.
7.4. Download data files¶
Download the file Guandong_Yearbook_2019.csv or from http://www2.geog.ucl.ac.uk/~plewis/GEOG0027/Guangdong-Yearbook-2019.csv and save it in the area where you are doing your work.
Remember the location where you are doing your work! (note it down).
You must also copy in a file of your classification results (a .csv file) to the local directory. This might typically be called results-2019.csv or a similar name. You will have generated it when performing the classification part of the practical.
It should be a csv format file, and should contain at least columns labelled year and urban_land:
Your file should look something like this:
index,year,urban_land
0,1987.0,511000.0
1,1988.0,520000.0
2,1989.0,595000.0
3,1990.0,656244.0
4,1991.0,725000.0
5,1992.0,780000.0
6,1993.0,842833.0
7,1994.0,938065.0
8,1995.0,1003711.0
7.5. Using Rstudio¶
If you are using Rstudio, run the software, and locate your data directory.
This must have the files Guangdong-Yearbook-2019.csv and results-2019.csv
You should then set this as the ‘working directory’
7.6. Using R¶
If you are using R directly:
* change directory to where you are doing your work, e.g.:
cd ~DATA/GEOG0027/gee
you should be able to simply type R in the terminal:
R
7.7. Modelling in R¶
Whether you are using R or Rstudio, the steps are now the same. In R, you type commands at the prompt. In Rstudio, you type commands in the console.
We will develop R codes to read and manipulate the data in the cells below.
[ ]:
############################
# First, change directory to where
# your (csv) files are
############################
# change working directory to
# where our files are
#
# Be careful with the setwd command
# and check where you are first
print('I am in:')
print(getwd())
# test for this file
test = "Guangdong-Yearbook-2019.csv"
# somewhere else it might be
# if its not here
# (put something appropriate!!)
sub = 'files'
if (test %in% list.files('.','*.csv')){
print(paste('found',test))
}else if (test %in% list.files(sub,'*.csv')){
print(paste('found',test,'in',sub))
setwd(sub)
print('I have moved to:')
print(getwd())
}
[3]:
############################
#
# Second, load the datasets:
#
# stats_file: files/Guangdong-Yearbook-2019.csv
# result_file: files/results-2019.csv
#
# N.B. YOU need to supply your own result_file
# DO NOT use the one provided here!!
#
############################
# The name of the file with year, urban_land and possibly agr_land
result_file <- 'results-2019.csv'
# the name of the supplied data file with Guandong stats
stats_file <- "Guangdong-Yearbook-2019.csv"
# load library
library(readr)
# read the datasets
Guangdong_Yearbook_2019 <- read_csv(stats_file)
input <- read_csv(result_file)
# fix the input dataset in case arg_land doesnt exist
if('agr_land' %in% names(input)){
print(paste('using agricultural land data from',results))
}else{
# If no ag land variable, insert one
print('inserting synthetic agricultural land data')
input$agr_land = 2 * max(input$urban_land) - input$urban_land
}
# The years in Guangdong_Yearbook_2019$year and
# input$year need to match
# so we force this with the match function in R
overlap <- match(Guangdong_Yearbook_2019$year,input$year,nomatch=0)
input <- input[overlap,]
Guangdong_Yearbook_2019 <- Guangdong_Yearbook_2019[overlap,]
# print the datasets to visualise and check it looks ok
print(input)
print(Guangdong_Yearbook_2019)
Parsed with column specification:
cols(
index = col_double(),
year = col_double(),
investment = col_double(),
population = col_double(),
private_wage = col_double(),
agr_output = col_double(),
indust_output = col_double(),
agr_pop = col_double(),
avg_wage = col_double()
)
Parsed with column specification:
cols(
index = col_double(),
year = col_double(),
urban_land = col_double()
)
[1] "inserting synthetic agricultural land data"
# A tibble: 14 x 4
index year urban_land agr_land
<dbl> <dbl> <dbl> <dbl>
1 0 1987 511000 3229000
2 1 1988 520000 3220000
3 2 1989 595000 3145000
4 3 1990 656244 3083756
5 4 1991 725000 3015000
6 5 1992 780000 2960000
7 6 1993 842833 2897167
8 7 1994 938065 2801935
9 8 1995 1003711 2736289
10 9 1996 1122459 2617541
11 10 1997 1250000 2490000
12 11 1998 1450000 2290000
13 12 1999 1650000 2090000
14 13 2000 1870000 1870000
# A tibble: 14 x 9
index year investment population private_wage agr_output indust_output
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 1987 251. 5832. 4.12 349. 878.
2 1 1988 354. 5928. 7.93 474. 1319.
3 2 1989 347. 6025. 13.3 549. 1647.
4 3 1990 381. 6246. 18.3 601. 1902.
5 4 1991 478. 6349. 28.2 655. 2524.
6 5 1992 922. 6463. 40.3 737. 3479.
7 6 1993 1630. 6582. 70.6 899. 5237.
8 7 1994 2141. 6691. 104. 1151. 7274.
9 8 1995 2327. 6789. 151. 1445. 9721.
10 9 1996 2328. 6897. 159. 1578. 10531.
11 10 1997 2298. 7014. 198. 1656. 12373.
12 11 1998 2668. 7116. 264. 1705. 13799.
13 12 1999 3028. 7299. 301. 1745. 15303.
14 13 2000 3234. 7499. 342. 1701. 16904.
# … with 2 more variables: agr_pop <dbl>, avg_wage <dbl>
[4]:
############################
#
# 3rd,
# form a data frame with the X datasets
# that we want (look at the formula)
# Note the use of input$agr_land
# and input$urban_land in here
#
############################
X = data.frame(year=Guangdong_Yearbook_2019$year,
x1=Guangdong_Yearbook_2019$investment/Guangdong_Yearbook_2019$population,
x2=Guangdong_Yearbook_2019$agr_output/Guangdong_Yearbook_2019$agr_pop,
x3=log(Guangdong_Yearbook_2019$private_wage),
x4=log(Guangdong_Yearbook_2019$avg_wage),
x5=(Guangdong_Yearbook_2019$agr_output/input$agr_land)/
(Guangdong_Yearbook_2019$indust_output/input$urban_land))
[5]:
############################
#
# 4th, our model needs the change in urban area
# with resect to year, which we might call du_dy
#
# to get this, we need to calculate du and dy
# i.e. the change ('delta') in urban area and year
#
# We will pack all of these datasets into a dataframe
# called model_data
#
############################
# Calculate the delta in year for observation data
# This will mostly be 1, but could be more
# if you have missing years
dy <- diff(input$year,differences = 1)
# Calculate the delta in urban land for observation data
du <- diff(input$urban_land,differences = 1)
# The rate of change of urban land per year
du_dy = du / dy
# reconstruct the observation year
# from the cumulative sum of dyear
# This should give a 'year' dataset
# with one fewer entry
obs_year <- data.frame(year=input$year[c(1)] + cumsum(dy))
# Now select all columns of X that match obs_year
# and call it model_data
overlap <- match(input$year,obs_year$year,nomatch=0)
model_data <- X[overlap,]
# and add in du_dy and dy to dataset
model_data$du_dy <- du_dy
model_data$dyear <- dy
model_data$urban_land <- input$urban_land[overlap]
# save this file
write.csv(model_data, file = "model-2019.csv")
[6]:
############################
#
# 5th, we do the linear modelling:
# multi linear fit of du_dy as function of X
# using the function lm and the x and y data
# stored in model_data
#
############################
# next time, you could skip all of the
# above and just load the model_data ...
library(readr)
model_data <- read_csv("model-2019.csv")
fit <- lm(du_dy ~ x1 + x2 + x3 + x4 + x5, data=model_data)
print(summary(fit))
Warning message:
“Missing column names filled in: 'X1' [1]”Parsed with column specification:
cols(
X1 = col_double(),
year = col_double(),
x1 = col_double(),
x2 = col_double(),
x3 = col_double(),
x4 = col_double(),
x5 = col_double(),
du_dy = col_double(),
dyear = col_double(),
urban_land = col_double()
)
Call:
lm(formula = du_dy ~ x1 + x2 + x3 + x4 + x5, data = model_data)
Residuals:
Min 1Q Median 3Q Max
-23328 -18491 -3506 7522 38790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1346051 2575068 0.523 0.617
x1 16800 337936 0.050 0.962
x2 802897 710485 1.130 0.296
x3 72200 103742 0.696 0.509
x4 -213235 367635 -0.580 0.580
x5 1761121 993690 1.772 0.120
Residual standard error: 27580 on 7 degrees of freedom
Multiple R-squared: 0.8961, Adjusted R-squared: 0.8218
F-statistic: 12.07 on 5 and 7 DF, p-value: 0.002475
[127]:
############################
#
# 6th, lets predict the du_dy from
# the model, and plot the measured and modelled
# values
#
############################
# predict from model
model_du_dy <- predict(fit, model_data)
plot(model_data$du_dy,model_du_dy
,xlab='observed du_dy / pixels',
,ylab='modelled du_dy / pixels') + abline(0,1,col="red")

[88]:
############################
#
# 6th, lets predict the du_dy from
# the model, and plot the measured and modelled
# values
#
############################
# Now reconstruct urban area from du_dy
modelled <- data.frame(year=model_data$year+dy[c(1)],
y=model_data$urban_land[c(1)] - model_du_dy[c(1)] + cumsum(model_du_dy))
measured <- data.frame(year=model_data$year,
y=model_data$urban_land)
# and plot the urban area measured and modelled
plot(modelled$year,modelled$y,pch=0
,xlab='year',
,ylab='urban land / pixels')
lines(modelled$year,modelled$y,col="red")
points(measured$year,measured$y,pch=1)
lines(measured$year,measured$y,,col="black")
legend(1988, 1800000, legend=c("modelled","measured"),
col=c("red", "black"), lty=1:2)

[89]:
fit$residuals
- 1
- -21062.0664341169
- 2
- 38789.8712455914
- 3
- 3908.36436144725
- 4
- -5431.76383748358
- 5
- -21424.3020238974
- 6
- -3474.84365337407
- 7
- 28146.5427634795
- 8
- -18490.9519028512
- 9
- -12560.864062646
- 10
- -23327.9740440934
- 11
- 30912.4809957813
- 12
- -3506.26475077546
- 13
- 7521.77134293876
7.8. Experimentation¶
The codes above allow you to fit the multi-linear model to the ‘observed’ values of change in urban area. These observations come from monitoring urban area using satellite (Landsat) data, then claculating the change per year (du_dy).
There are a few new functions, but most of the functions (including lm) should be familiar to you from the stats you did in the 1st year.
You should first familiarise yourself with the code blocks, and make sure the code works properly on the dataset you have generated.
The main result at this point is, in many ways, simply the plots and the statistics generated by print(summary(fit)) above. But rather than just ‘running’ this and pasting the results into your report, you will need to demonstrate that you understand what is going on. This means you must provide a full description of what you are doing, along with the R code. You should interpret the statistics. Given output such as:
Residual standard error: 27580 on 7 degrees of freedom
Multiple R-squared: 0.8961, Adjusted R-squared: 0.8218
F-statistic: 12.07 on 5 and 7 DF, p-value: 0.002475
Residuals:
Min 1Q Median 3Q Max
-23328 -18491 -3506 7522 38790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1346051 2575068 0.523 0.617
x1 16800 337936 0.050 0.962
x2 802897 710485 1.130 0.296
x3 72200 103742 0.696 0.509
x4 -213235 367635 -0.580 0.580
x5 1761121 993690 1.772 0.120
7.8.1. The sort of questions you should ask of the data / results¶
What are the numbers we should be looking at to interpret different features of the model?
First, let’s consider:
What does `Adjusted R-squared` tell us?
You may need to look this up to get a formal definition, but you should at least note that it is a measure of goodness of fit of the model to the observations, that has some account taken of the number of model parameters.
Why do you need to take account of the number of parameters?
An interesting question following on from thinking about Adjusted R-squared is:
Can we form a model with fewer parameters, but a lower Adjusted R-squared?
An example of this is:
[129]:
# original model
fit <- lm(du_dy ~ x1 + x2 + x3 + x4 + x5, data=model_data)
model_du_dy <- predict(fit, model_data)
print(fit$call)
print(summary(fit)$adj.r.squared)
# lets try another model
fit1 <- lm(du_dy ~ x2 + x3 + 0 , data=model_data)
model_du_dy1 <- predict(fit1, model_data)
print(fit1$call)
print(summary(fit1)$adj.r.squared)
lm(formula = du_dy ~ x1 + x2 + x3 + x4 + x5, data = model_data)
[1] 0.8218426
lm(formula = du_dy ~ x2 + x3 + 0, data = model_data)
[1] 0.9356219
So, the model du_dy = p2 x2 + p3 x3 is seemingly ‘better’ than the full model.
This suggests that (in this case) rather than simply accept the full model, we shouyld try to develop an improved, reduced model.
With different input values, you will likely get different resulrts for the ‘best’ model, but you will still need to experiment with the model terms to justify a final model choice.
Additional questions:
What do the parameters tell us?
What is their 'physical' meaning? (and units)
Are the paremeter values statistically significant (at some given level)?
What is the standard error of the parameters?
What does `Pr(>|t|)` tell us?
What are the `F-statistic` and `p-value` terms telling us?
Relate this to what you can see in any graphs of the data and model.
You should also look at residuals (fit$residuals) to see if there might be any ‘outliers’ in your data (e.g. values of urban area that just don’t fit the general pattern and are likely to be errors in interpretation of the Landsat data). If you wish to discard any points from the analysis (e.g. outliers) make sure you provide sufficient justification (e.g. show the classified images to demonstrate why a particular data is ‘wrong’ (a mis-interpretation).
7.8.2. Additonal experiments¶
So long as you have covered the basic requirements, you can aim for higher marks by completing some additional analysis. The amount of extra marks would be a function of the relevance of the experiments (so, explain the relevance) and how well you have executed and described them.
One example that you might consider:
7.8.2.1. Improved model testing¶
The model we have developed so far used all of the data points for model calibration. The statistics we looked at above can tell us something about the performance and value of the model, but it is often better to seek independent confirmation of model performance.
In this case, that would mean, for example, taking the first N years of data to calibrate the model, and using the last M years to test the model, where N + M = number of years of data.
Ther code below shows how to set up fitting and testing for sub-datasets (the first N years for calibration and the remainder for validation). We leave it to the student to quantify the goodness of fit of the validation data, which should clearly be part of any assessment.
[216]:
#########################
#
# We can take a subset of data
# from model_data
#
#########################
# a utility function: last + first elements
last <- function(x) { tail(x, n = 1) }
first <- function(x) { head(x, n = 1) }
subber <- function(N,model_data){
ystart = first(model_data$year)
yend = last(model_data$year)
M = yend - ystart - N
# sub-dataset for year from ystart for count years
train = model_data[model_data$year %in% seq(ystart,ystart+N-1),]
test = model_data[model_data$year %in% seq(ystart+N+1,yend),]
#########################
#
# train
#
#########################
fits <- lm(du_dy ~ x1 + x2 + x3 + x4 + x5,train)
# or another model?
# fits <- lm(du_dy ~ x2 ,train)
my_list <- list('train'=train,'test'=test,'fits'=fits)
return(my_list)
}
[219]:
# N needs to be *at least* the number
# of parameters + 1 and more like 2 x
# the number of parameters or more
N = 9
# get subset
sub <- subber(N,model_data)
# training
train_du_dy <- predict(sub$fits, sub$train)
# validation
test_du_dy <- predict(sub$fits, sub$test)
# max value for plotting
m = max(c(train_du_dy,test_du_dy,sub$train$du_dy,sub$test$du_dy))
# plotting in R
plot(sub$train$du_dy,train_du_dy
,xlim=c(0,m),ylim=c(0,m)
,xlab='observed du_dy / pixels',
,ylab='modelled du_dy / pixels') + abline(0,1,col="red")
title('Calibration and validation')
points(sub$test$du_dy,test_du_dy,col='green',pch=2)
legend(0, m*4/6, legend=c("calibration","validation"),
col=c( "black", 'green'),pch=c(1,2))
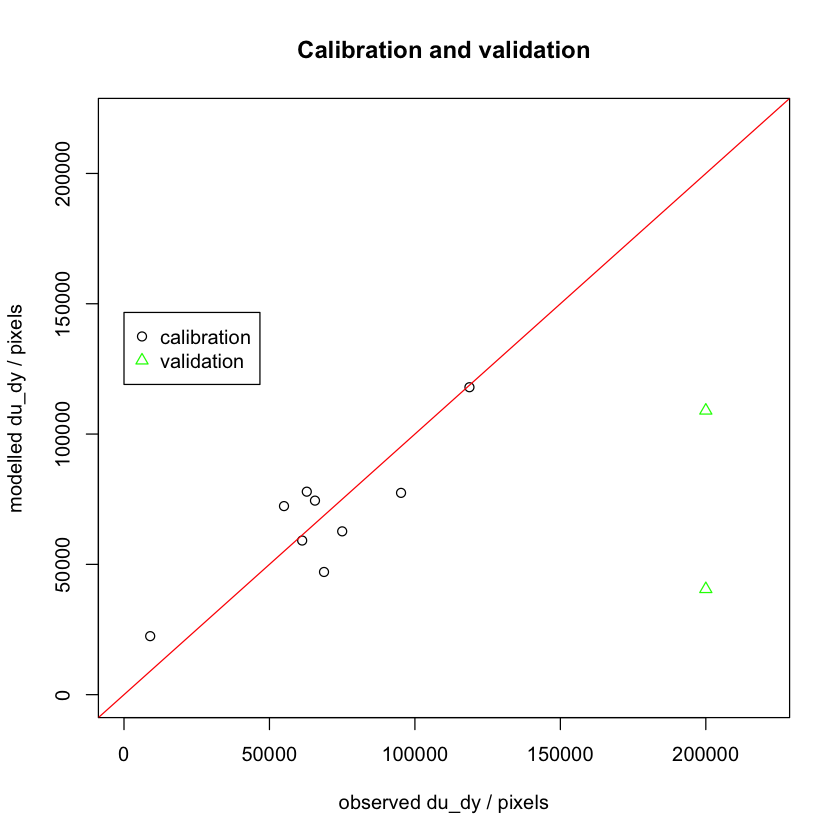
You should note the validation behaviour as you increase/decrease N.
It is also important for you to understand what happens at low N:
If `N` is less than the number of model parameters, what happens?
7.9. Summary¶
In this section, we have phrased the linear model of Seto et al. within R’s lm function:
du_dy ~ x1 + x2 + x3 + x4 + x5
The model relates socio-economic variables (constant, plus x1, x2, x3, x4, x5), weighted by model parameters (p0, p1, p2, p3, p4, p5) to predict the rate if change of urban area per year (du_dy).
We have taken a set of observations of du_dy, derived from Landsat land cover classifications for the years 1986 to present. Along with estimates of the x variables from the Guangdong yearbook, we have then seen how to produce an esrimate of the model parameters (the p terms).
This forms the basis of the modelling section of this coursework: As noted above, you need to perform a model calibration, plot results, and describe and interpret summary statistics. Your interpretation of the statistics is vital here as it will show your understanding of the terms printed. Your plots should be neatly done, with full axis labelling, titles etc, noting any units or scaling factors used.
We have given you a set of questions to help guide your statistical interpretation.
You are then required to see if you can come up with a model with fewer parameters. The original model has 6 parameters, but it could well be the case that we can develop a more robust model with fewer parameters. One way we can judge ‘better’ here is to take a measure of goodness of fit that accounts for the model degrees of freedom: ‘better’ then is a balance of these things.
You are free to perform additional experiment, with the expectation of higher marks, provided (i) you have done the basic requirements well enough, and (ii) you show clarity of thoiught and understanding of what you are doing in your experiments.